当需要一下子返回所有内容的聚合函数时,就涉及到数据分组了
1.创建分组
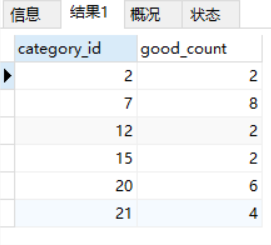
SELECT category_id, COUNT(*) FROM goods_goods GROUP BY category_id;
根据商品的类型,统计商品的数量。GROUP BY子句指示数据库按category_id排序并分组数据。
GROUP_BY的注意事项:
- GROUP BY子句可以包含任意数目的列,因而可以对分组进行嵌套,更好的进行数据分组
- 如果在GROUP BY子句中嵌套分组,数据将在最后指定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算
- GROUP BY子句中列出的每一项都必须是检索列或有效的表达式(但不能是聚合函数)。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名
- 大多数SQL实现不允许GROUP BY列带有长度可变的数据类型(如文本或备注型字段)
- 除聚集计算语句外,SELECT语句中的每一列都必须在GROUP BY子集中给出
- 如果分组列中包含具有NULL值的列,则NULL将作为一个分组返回。如果列中有多行NULL,它们将分为一组
- GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
3.过滤分组
除了能用GROUP BY分组数据外,SQL还允许过滤分组,规定包括那些分组,排除那些分组。
过滤分组使用HAVING,HAVING非常类似WHERE,事实上所有类型的WHERE子句都可以使用HAVING替代。唯一区别在于WHERE过滤行,而HAVING过滤分组。
SELECT category_id, COUNT(*) AS good_count FROM goods_goods GROUP BY category_id HAVING COUNT(*) > 2;
从返回的商品数量中过滤出大于2件商品的类型。
下一个例子,展示WHERE和HANGING的不同
SELECT category_id, COUNT(*) AS good_count FROM goods_goods WHERE shop_price > 50
GROUP BY category_id HAVING COUNT(*) > 2;
GROUP BY category_id HAVING COUNT(*) > 2;
首先从商品表中过滤掉价格小于50的,在对剩下的商品进行分组。
4.分组和排序
GROUP BY和ORDER BY经常完成相同的工作,但它们非常不同。如下表:
| ORDER BY | GROUP BY |
| 对产生的输出排序 | 对行分组,但输出可能不是分组的顺序 |
| 任意列都可以使用(非选择的列也可以使用) | 只可能使用选择列或表达式列,且必须使用每个选择列表达式 |
| 不一定需要 | 如果与聚合函数一起使用列(或表达式),则必须使用 |
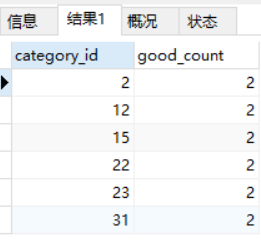
以1.创建分组中的图来作对比,展示这二者的区别
SELECT category_id, COUNT(*) AS good_count FROM goods_goods
GROUP BY category_id ORDER BY good_count, category_id;
GROUP BY category_id ORDER BY good_count, category_id;
SELECT子句总结
| 子句 | 说明 | 是否必须使用 |
| SELECT | 要返回的列或表达式 | 是 |
| FROM | 从中检索数据的表 | 仅在从表选择数据时使用 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅在按组计算聚集时使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 输出排序顺序 | 否 |
评论列表
已有0条评论