爬虫的工作流程是:
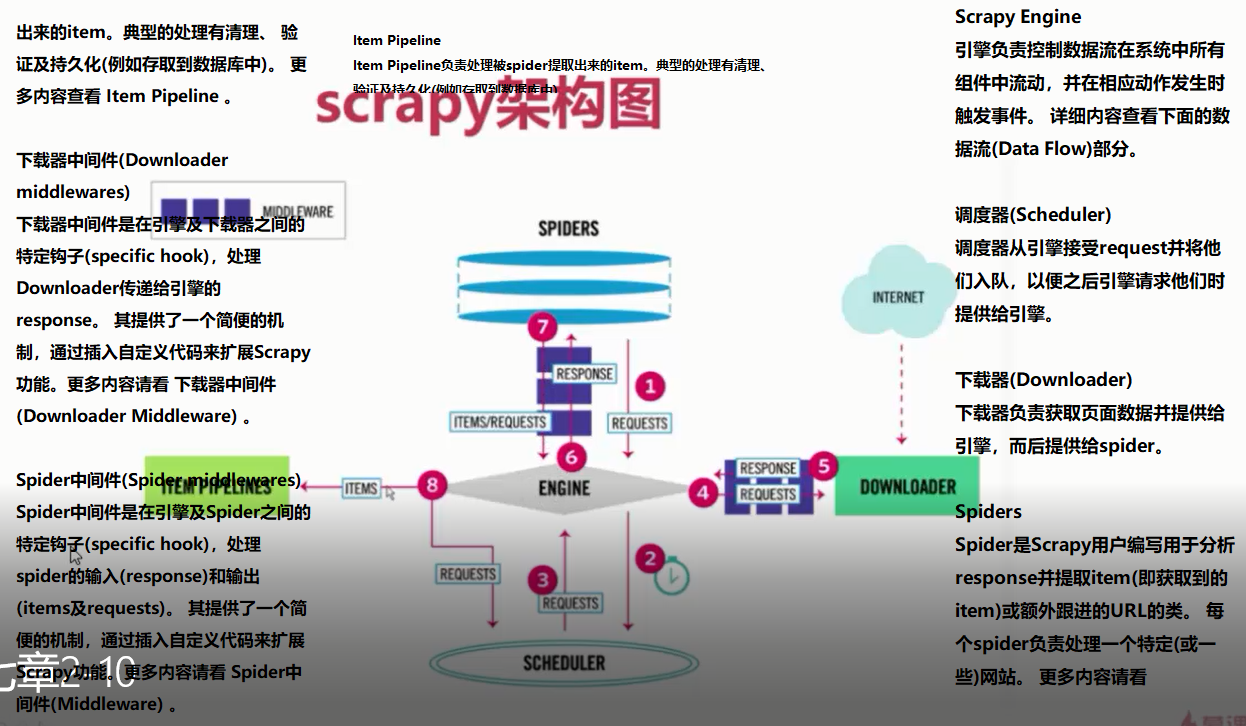
1.spider.py:用户编写提取网页字段的解析函数,这里会产生request,可以理解为链接
2.经过middleware,到达引擎,发送到scheduler入队,经过引擎到达下载器的middleware,下载器访问链接,获取网页数据
3.获得数据response,返回到spider.py中,这一步后会经过items,在piplines中可以保存数据,使用piplines需要到setting.py中
取消注释
解释一下scrapy的爬取方式。
1.在item.py中设置爬取数据的字段。
这是我爬取58同城的房源数据。
title = scrapy.Field(
input_processor = MapCompose(strip_blank)
)
url = scrapy.Field()
hourse_type = scrapy.Field(
input_processor = MapCompose(strip_blank)
)
area = scrapy.Field()
direction = scrapy.Field()
position = scrapy.Field()
addr = scrapy.Field(
input_processor = MapCompose(remove_tags)
)
broker = scrapy.Field()
company = scrapy.Field()
total = scrapy.Field()
per_square_metre = scrapy.Field()
但是我不得不说,上面的input_processor没有生效,这与你在spider.py中编写的方式密切相关。
下面是scrapy.py的代码
from wubacity.items import WubacityItem
class CitySpider(scrapy.Spider):
name = 'city'
allowed_domains = ['https://jingzhou.58.com/']
start_urls = ['https://wh.58.com/ershoufang/pn1/']
def parse(self, response):
# item_loader = ItemLoader()
item = WubacityItem()
# response = response.body.decode('utf-8')
all_hourse = response.css(".house-list-wrap li")
for i in all_hourse:
title = i.css('h2.title a::text').extract()[0]
url = i.css('h2.title a::attr(href)').extract()[0]
hourse_type = i.xpath(".//*[@class='baseinfo']/span[1]/text()").extract_first()
area = i.xpath(".//*[@class='baseinfo']/span[2]/text()").extract()[0]
direction = i.xpath(".//*[@class='baseinfo']/span[3]/text()").extract()[0]
position = i.xpath(".//*[@class='baseinfo']/span[4]/text()").extract_first()
total = i.css(".price p.sum b::text").extract_first()
per_square_metre = i.css(".price p.unit::text").extract_first()
addr = i.xpath(".//*[@class='list-info']/p[2]/span/a").extract()
broker = i.xpath(".//*[@class='jjrname-outer']/text()").extract_first()
company = i.css(".anxuan-qiye-text::text").extract_first()
# print(title, hourse_type, area, direction, position, total, per_square_metre,
# addr, broker, company)
item['title'] = title.strip()
item['url'] = url
item['hourse_type'] = hourse_type
item['area'] = area.strip()
item['direction'] = direction
item['position'] = position
item['total'] = total
item['per_square_metre'] = per_square_metre
item['addr'] = addr
item['broker'] = broker
item['company'] = company
yield item
next_url = response.css(".next::attr(href)").extract_first()
if next_url:
yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse, dont_filter=True)
scrapy在爬取时,parse方法是先执行的,在spider.py中一般编写解析网页的数据,当然你也可以在其中编写清洗数据的函数,但大多数人不推荐在这里清洗数据。数据一般放在item.py或者piplines.py中处理。使用item类其实蛮麻烦的,容易混乱,而且,不可以在item.py中处理数据。
这时,可以使用ItemLoader。
下方是豆瓣电影的爬虫:
from scrapy.loader import ItemLoader
class DoubanMovieSpider(scrapy.Spider):
name = 'douban_movie'
allowed_domains = []
start_urls = ['http://movie.douban.com/top250/']
def parse(self, response):
content = response.xpath('//ol[@class="grid_view"]/li')
for i in content:
l = ItemLoader(item=MyprojectItem(), selector=i)
使用item容器
item['movie_name'] = i.xpath('.//div[@class="hd"]/a/span[1]/text()').extract()
item['rating_num'] = i.xpath('.//*[@class="star"]/span[2]/text()').extract()
item['inq'] = i.xpath('.//span[@class="inq"]/text()').extract()
item['contents'] = i.xpath('.//div[@class="star"]/span[4]/text()').extract()
item['images_url'] = i.xpath('.//div[@class="pic"]/a/img/@src').extract()
yield item
使用itemloader
l.add_xpath('movie_name', './/div[@class="hd"]/a/span[1]/text()')
l.add_xpath('rating_num', './/*[@class="star"]/span[2]/text()')
l.add_xpath('inq', './/span[@class="inq"]/text()')
l.add_xpath('contents', './/div[@class="star"]/span[4]/text()')
l.add_xpath('images_url', './/div[@class="pic"]/a/img/@src')
yield l.load_item()
next_page = response.xpath('//span[@class="next"]/a/@href').extract_first()
if next_page:
urls = self.start_urls[0] + next_page
yield Request(urls, callback=self.parse)
itemloader可以将爬取到的数据,放入item,这时可以在item.py中处理数据了。
2.关于下一页的爬取
在起始页面中找到下一页,获取下一页的链接,如果链接不完整,使用第一个代码中的parse.urljoin(response.url, next_url)进行链接拼接,有就回调parse方法。
评论列表
已有0条评论