1.DetailView类
看意思应该可以猜到是与详情有关的视图类。
用法如下:
models.py
class BookType(models.Model):
book_type = models.CharField(max_length=50)
add_time = models.DateTimeField()
def __str__(self):
return self.book_type
class Book(models.Model):
book_type = models.ForeignKey(BookType, on_delete=models.DO_NOTHING)
name = models.CharField(max_length=150)
author = models.CharField(max_length=100)
add_time = models.DateTimeField(auto_created=True)
def __str__(self):
return self.name
urls.py
urlpatterns = [
path('book_type/', BookTypeView.as_view()), # 分类
path('book/<int:id>', DetailViewTest.as_view(), name='book2'), # 详情
path('book_list/', BookListView.as_view(), name='list_book') # 列表
]
views.py
分类
class BookTypeView(View):
def get(self, request):
booktypes = BookType.objects.all()
return render(request, 'book1.html', {"book_types": booktypes})
前端效果部分

关于detailview部分
class DetailViewTest(DetailView):
model = Book
template_name = "book2.html"
context_object_name = 'obj' # 对应book2.html中的obj
# slug在是为了展示更友好的url而产生的
slug_field = 'id' # 需要查询的字段
slug_url_kwarg = 'id' # 为url中具体的值,/post/a/b, 则b为slug
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context['now'] = timezone.now()
return context
一般来说,详情都是使用pk来查询的,比如/book1/1,这种形式的url。当然DetailView默认也是使用pk来查询的,这里为了演示slug故使用slug_field。
DetailView的源码中有以下类方法:
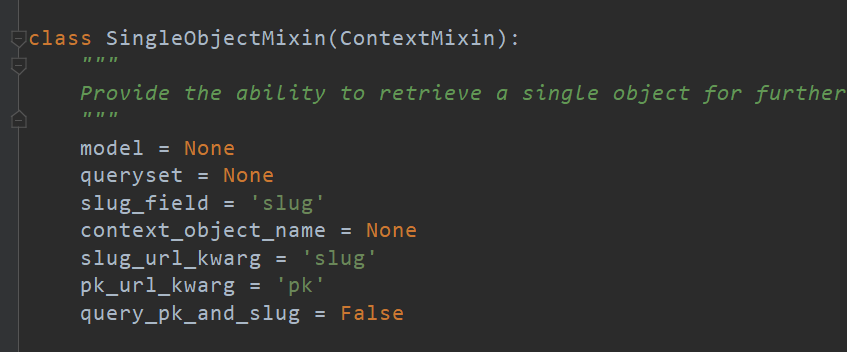
model,需要指定的表
queryset,默认取该表的全部字段,其类型可以理解为1个特殊的列表

slug_field,查询的字段,以下为我的个人理解:
slug与pk可以是差不多的,但是pk与slug相比,存在很多限制
对于访问详情页来说,使用DetailView类是非常简单的,DetailView已经封装好了,包括/pk等方法,你只要定义model和template_name
剩下的事情,就交给该类来做,context_object_name='obj',则html页面就是{{obj.field}},默认是object
query_pk_and_slug,作用是如果为真,则导致get_object()同时使用主键和slug执行查找。默认值为False。 此属性有助于减轻不安全的直接对象引用攻击。当应用程序允许通过连续的主键访问单个对象时,攻击者可以强行猜测所有url;从而获得应用程序中所有对象的列表。如果应该阻止访问单个对象的用户获得这个列表,那么将query_pk_and_slug设置为True将有助于防止猜测URL,因为每个URL都需要两个正确的、不连续的参数。使用唯一的段塞可以达到同样的目的,但是这个方案允许您使用非唯一的查询条件
if slug is not None and (pk is None or self.query_pk_and_slug):
slug_field = self.get_slug_field()
queryset = queryset.filter(**{slug_field: slug})
template
<div>{{ obj.now }}</div>
<div>{{ obj.author }}</div>
<div>{{ obj.name }}</div>
2.ListView
类属性:
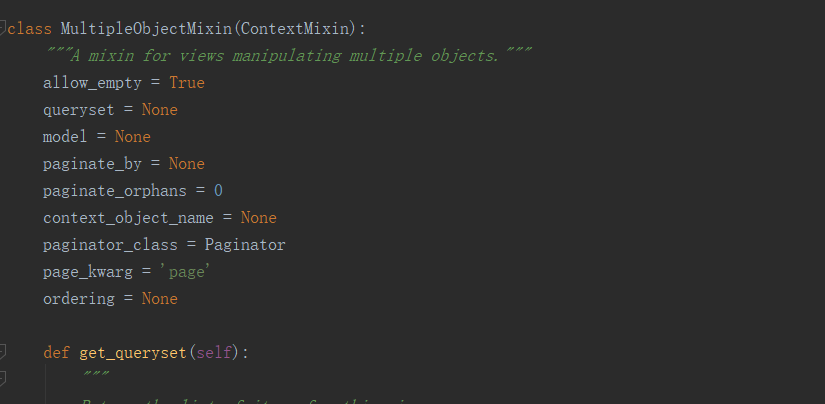
view.py
class BookListView(ListView):
model = Book
template_name = 'book3.html'
paginate_by = 2 # 每页多少数据
page_kwarg = 'pages' # 自定义url查询字段,如?pages=1
# queryset = '' 可以指定查询的内容 Book.object.
# orphans=0:当你使用此参数时说明你不希望最后一页只有很少的条目。如果最后一页的条目数少于等于orphans的值,
# 则这些条目会被归并到上一页中(此时的上一页变为最后一页)。例如有23项条目, per_page=10,orphans=0,则有3页,
# 分别为10,10,3.如果orphans>=3,则为2页,分别为10,13。
paginate_orphans = 1
# queryset = Book.objects.filter(author='lx') # 查询作者为lx
# ordering # 以某个字段来排序,默认为pk
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context['now'] = timezone.now()
return context
html:
<body>
<h1>Books</h1>
<ul>
{% for book in object_list %}
<li>{{ book.author }}--{{ book.book_type }}--{{ book.name }}</li>
{% empty %}
<li>No articles yet.</li>
{% endfor %}
</ul>
</body>
评论列表
已有0条评论